
发布时间:2025.07.15
源地址:https://blog.cloudflare.com/cloudflare-1-1-1-1-incident-on-july-14-2025/
2025 年 7 月 14 日,Cloudflare 对我们的服务拓扑结构进行了调整,导致边缘节点上的 1.1.1.1 出现故障,使用 1.1.1.1 公共 DNS 解析器的客户服务中断了 62 分钟,同时 Gateway DNS 服务也出现了间歇性性能下降。
Cloudflare 的 1.1.1.1 解析服务从协调世界时 21:52 开始中断,至 22:54 恢复。全球大多数 1.1.1.1 用户受到影响。对于许多用户来说,无法通过 1.1.1.1 解析服务解析域名,意味着几乎所有互联网服务都无法使用。此次故障可在 Cloudflare Radar 上观察到。
此次故障是由于用于维护向互联网发布 Cloudflare IP 地址的基础设施的传统系统配置错误所致。
这是一次全球范围的故障。在故障期间,Cloudflare 的 1.1.1.1 解析器在全球范围内无法使用。
我们对这次故障深表歉意。根本原因是内部配置错误,而非攻击或 BGP 劫持所致。在本文中,我们将介绍故障的具体情况、发生原因,以及我们为防止类似事件再次发生所采取的措施。
背景介绍
Cloudflare 于 2018 年推出了 1.1.1.1 公共 DNS 解析服务。自发布以来,1.1.1.1 已成为最受欢迎的 DNS 解析 IP 地址之一,任何人均可免费使用。
几乎所有 Cloudflare 的服务都通过一种称为 anycast 的路由方式向互联网提供。这是一种广为人知的技术,旨在让热门服务的流量能够在互联网上多个不同地点进行处理,从而提升容量和性能。这是确保我们能够全球范围内管理流量的最佳方式,但也意味着如果该地址空间的广告出现问题,可能会导致全球范围的中断。
Cloudflare 宣布将这些 Anycast 路由发布到互联网,以便将发往这些地址的流量传送到 Cloudflare 的数据中心,从而在多个地点提供服务。大多数 Cloudflare 服务是全球范围内提供的,例如 1.1.1.1 公共 DNS 解析器,但部分服务则专门限制在特定区域内。
这些服务是我们数据本地化套件(Data Localization Suite,简称 DLS)的一部分,允许客户以多种方式配置 Cloudflare,以满足不同国家和地区的合规需求。Cloudflare 管理这些不同需求的方式之一,是确保特定服务的 IP 地址仅在必要的地区可通过互联网访问,从而确保您的流量在全球范围内得到正确处理。每个特定服务都有相应的“服务拓扑”——即该服务的流量应仅路由到特定的一组位置。
6 月 6 日,在为未来的 DLS 服务准备服务拓扑的发布过程中,引入了一个配置错误:与 1.1.1.1 解析器服务相关的前缀被误包含在原本用于新 DLS 服务的前缀中。由于新 DLS 服务尚未启用,这一配置错误在生产网络中处于未激活状态,但为 7 月 14 日的故障埋下了隐患。由于生产网络没有立即发生变化,最终用户未受到影响,也因此没有触发任何警报。
事件时间线
影响
通过这些 IP 地址上的 1.1.1.1 解析器服务访问 Cloudflare 的所有流量均受到影响。访问这些地址的流量在相应路由上也受到影响。
1.1.1.0/24 1.0.0.0/24 2606:4700:4700::/48 162.159.36.0/24 162.159.46.0/24 172.64.36.0/24 172.64.37.0/24 172.64.100.0/24 172.64.101.0/24 2606:4700:4700::/48 2606:54c1:13::/48 2a06:98c1:54::/48
当冲击开始时,我们观察到通过 UDP、TCP 以及基于 TLS 的 DNS(DoT)的查询量立即且显著下降。大多数用户将 1.1.1.1、1.0.0.1、2606:4700:4700::1111 或 2606:4700:4700::1001 配置为他们的 DNS 服务器。下方展示了各个协议的查询速率及其在事件期间受到的影响情况:
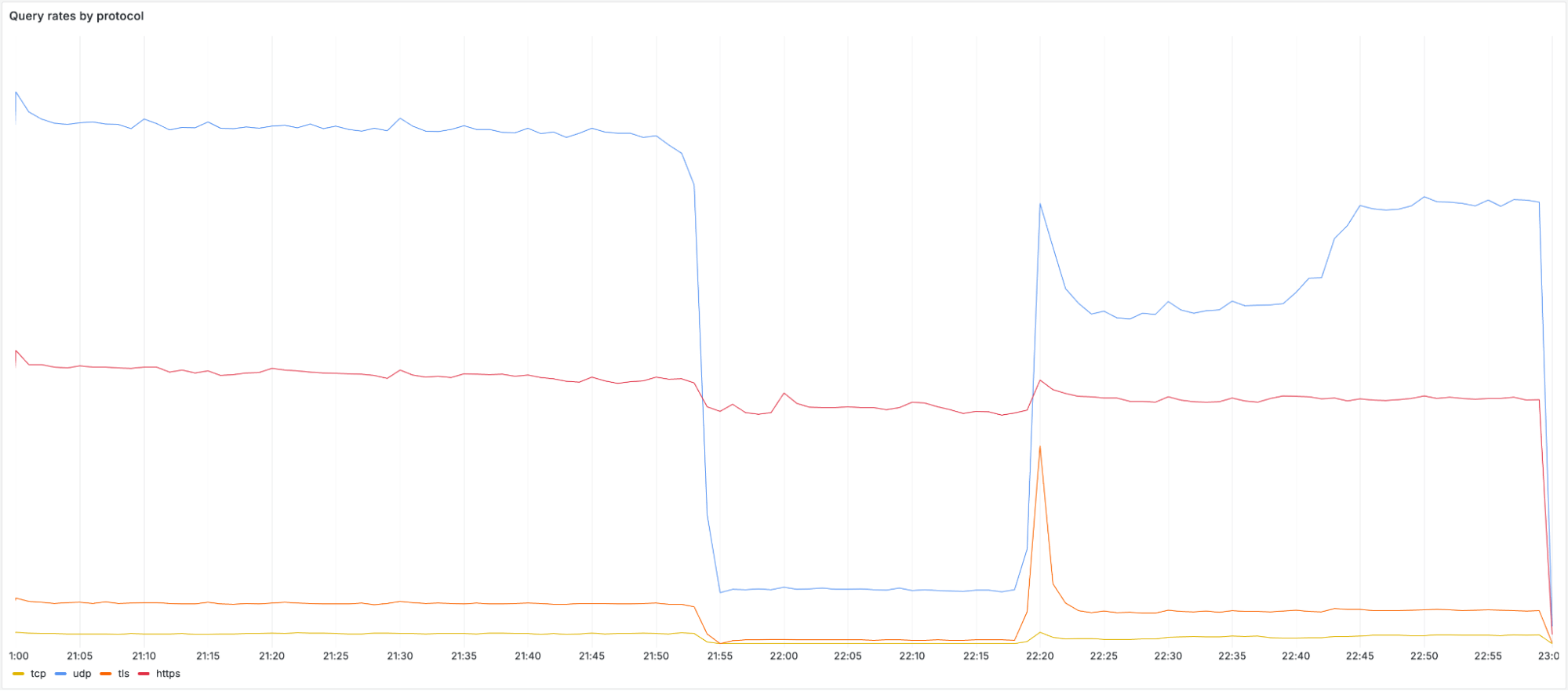
值得注意的是,DoH(通过 HTTPS 的 DNS)流量保持相对稳定,因为大多数 DoH 用户通过手动配置或浏览器设置,使用域名 cloudflare-dns.com 访问公共 DNS 解析器,而非直接使用 IP 地址。DoH 服务依然可用,流量基本未受影响,因为 cloudflare-dns.com 使用的是一组不同的 IP 地址。同时,一些通过 UDP 传输且使用不同 IP 地址的 DNS 流量也基本未受影响。
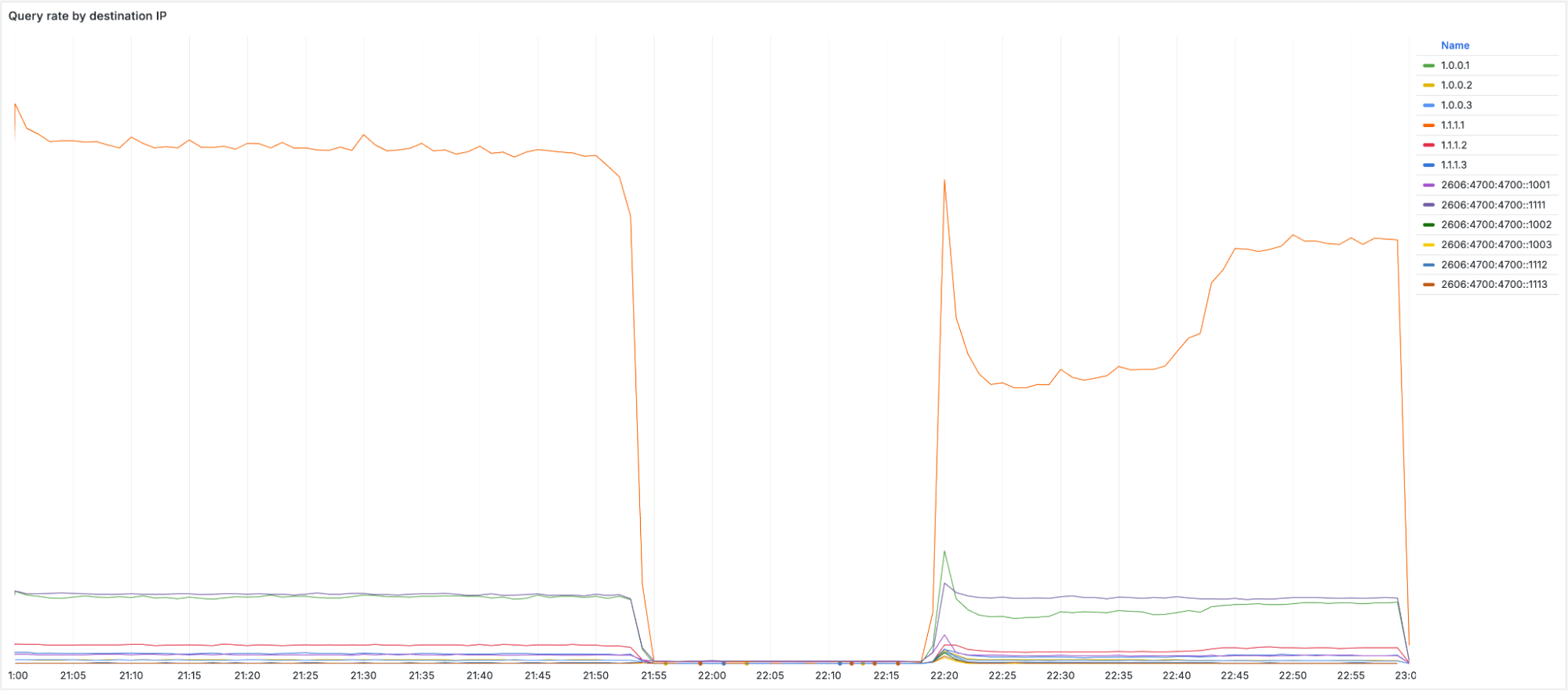
随着相应的前缀被撤回,发送到这些地址的流量无法到达 Cloudflare。我们可以从 1.1.1.0/24 的 BGP 公告时间线上看到这一点:

上图展示了全球范围内 BGP 撤销及 1.1.1.0/24 前缀重新公告的时间线
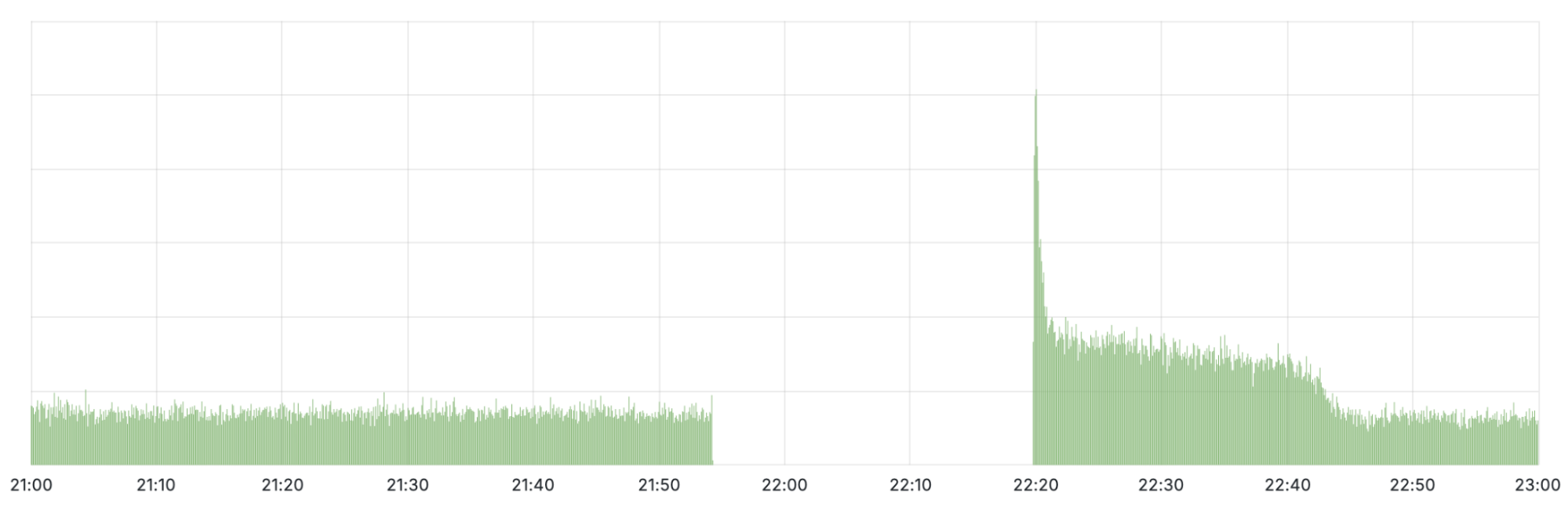
在观察被撤回 IP 的查询率时,可以发现几乎在影响时间窗口内没有流量到达。当初始修复于协调世界时 22:20 施行时,流量出现了一个大幅峰值,随后又迅速下降。该峰值是由于客户端重试查询所致。当我们开始重新宣布被撤回的前缀时,查询再次能够到达 Cloudflare。直到协调世界时 22:54,所有地区的路由才恢复,流量基本回归正常水平。
错误的技术描述及其发生原因
1.1.1.1 解析服务故障
如上所述,6 月 6 日的一次配置变更在预生产的 DLS 服务的服务拓扑中引入了错误。7 月 14 日,对该服务进行了第二次变更:为了进行一些内部测试,向预生产 DNS 服务的服务拓扑中添加了一个离线的数据中心位置。此变更触发了相关路由的全局配置刷新,正是在此时,之前配置错误的影响开始显现。1.1.1.1 解析器前缀的服务拓扑从所有位置缩减到仅一个离线位置,导致所有 1.1.1.1 前缀被全球范围内立即撤回。
随着通往 1.1.1.1 的路由被撤销,1.1.1.1 服务本身变得不可用。警报触发,事件被宣布。
技术调查与分析
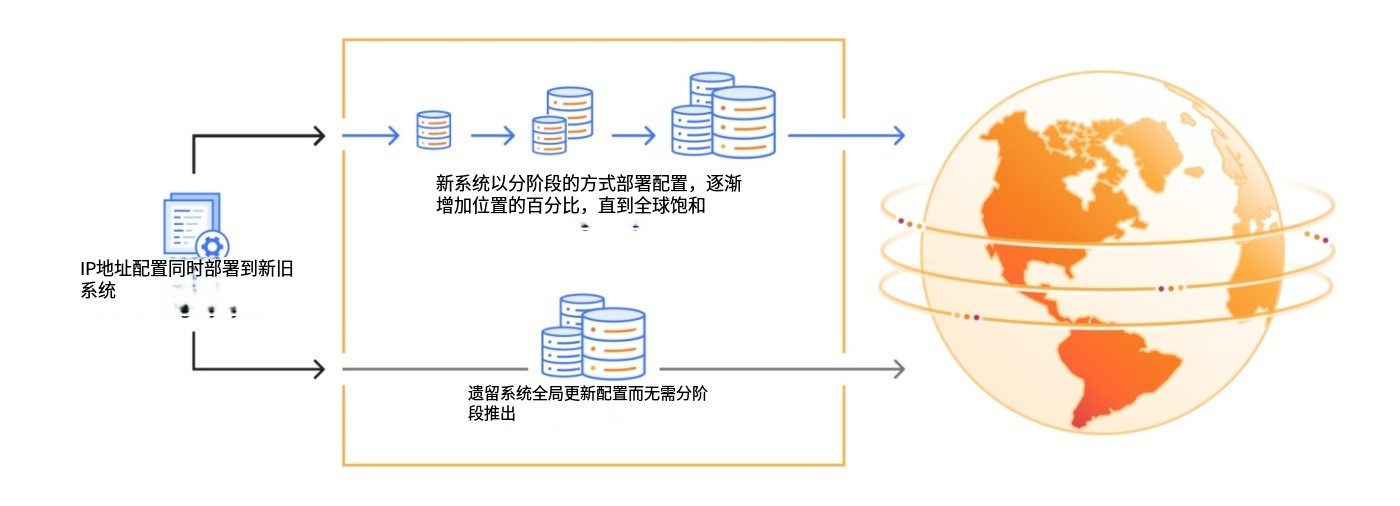
Cloudflare 管理服务拓扑的方式经过不断完善,目前采用的是遗留系统与战略系统相结合并同步运行的模式。Cloudflare 的 IP 范围目前绑定并配置在这些系统中,用以决定某个 IP 范围应在边缘网络的哪个数据中心位置进行公告。遗留方法是通过硬编码明确的数据中心位置列表并将其附加到特定前缀上,但这种方式容易出错,例如上线新数据中心时需要更新并同步多个不同列表。该模型的另一个显著缺陷是配置更新不遵循渐进式部署方法:尽管此次发布经过多位工程师的同行评审,但变更并未经过一系列金丝雀部署就直接推送到所有 Cloudflare 数据中心。我们较新的方法是描述服务拓扑时无需硬编码 IP 地址,这不仅更好地支持新地点和客户场景的扩展,还允许采用分阶段部署模式,使变更能够缓慢传播并配合健康监控。在这两种方法迁移期间,我们需要同时维护两个系统并同步它们之间的数据,具体流程如下:
最初的警报于 22:01 触发,指示 DNS 解析器出现查询、代理和数据中心故障。在调查警报时,我们注意到指向解析器前缀的流量急剧下降,且边缘数据中心不再接收到相关流量。内部方面,我们使用 BGP 控制路由公告,发现服务器发出的解析器路由完全消失。
一旦我们的配置错误被暴露,且 Cloudflare 系统从我们的路由表中撤销了相关路由,所有 1.1.1.1 路由本应完全从全球互联网路由表中消失。然而,1.1.1.0/24 前缀的情况并非如此。相反,我们从 Cloudflare Radar 收到报告称,印度 Tata Communications(AS4755)开始宣布 1.1.1.0/24:从路由系统的角度来看,这看起来完全像是一次前缀劫持。这在我们排查路由问题时是意料之外的,但需要明确的是:此次 BGP 劫持并非导致故障的原因。我们正在与 Tata Communications 跟进此事。
恢复 1.1.1.1 服务
我们于协调世界时 22:20 恢复了之前的配置。几乎立刻,我们开始重新发布之前从路由器中撤回的 BGP 前缀,包括 1.1.1.0/24。这使得 1.1.1.1 的流量水平恢复到事件发生前的大约 77%。然而,在撤回期间,大约 23%的边缘服务器因拓扑结构变化被自动重新配置,移除了必要的 IP 绑定。要重新添加这些配置,必须通过我们的变更管理系统对这些服务器进行重新配置,而该过程出于安全考虑,默认并非即时完成。
IP 绑定的恢复过程通常需要一定时间,因为各地网络的更新设计为分多个小时逐步完成。我们采用渐进式部署,而非一次性在所有节点上更新,以避免带来额外影响。然而,鉴于事件的严重性,在测试地点验证变更后,我们加快了修复方案的推广速度,力求尽快且安全地恢复服务。正常流量水平于协调世界时 22:54 恢复。
补救措施及后续步骤
我们高度重视此类事件,并充分认识到该事件所带来的影响。虽然此次具体问题已得到解决,但我们已确定了多项措施,以降低未来发生类似问题的风险。基于此次事件,我们正在实施以下计划:
分阶段部署问题:传统组件未采用渐进式、分阶段的部署方法。Cloudflare 将逐步淘汰这些系统,以支持现代的渐进式和健康监测部署流程,从而实现分阶段的早期预警和相应的回滚。
我们目前处于一个过渡阶段,现有系统和旧有组件需要同时更新,因此我们将逐步淘汰像当前这种存在风险的部署方式。我们将加快废弃旧系统的进程,以提升文档编写和测试覆盖的标准。
结论
Cloudflare 的 1.1.1.1 DNS 解析服务因内部配置错误而中断。
我们对本次事件给客户带来的不便深表歉意。我们正在积极进行改进,以确保未来服务的稳定性,并防止类似问题再次发生。